Article
The Mozilla Blog
(2019)
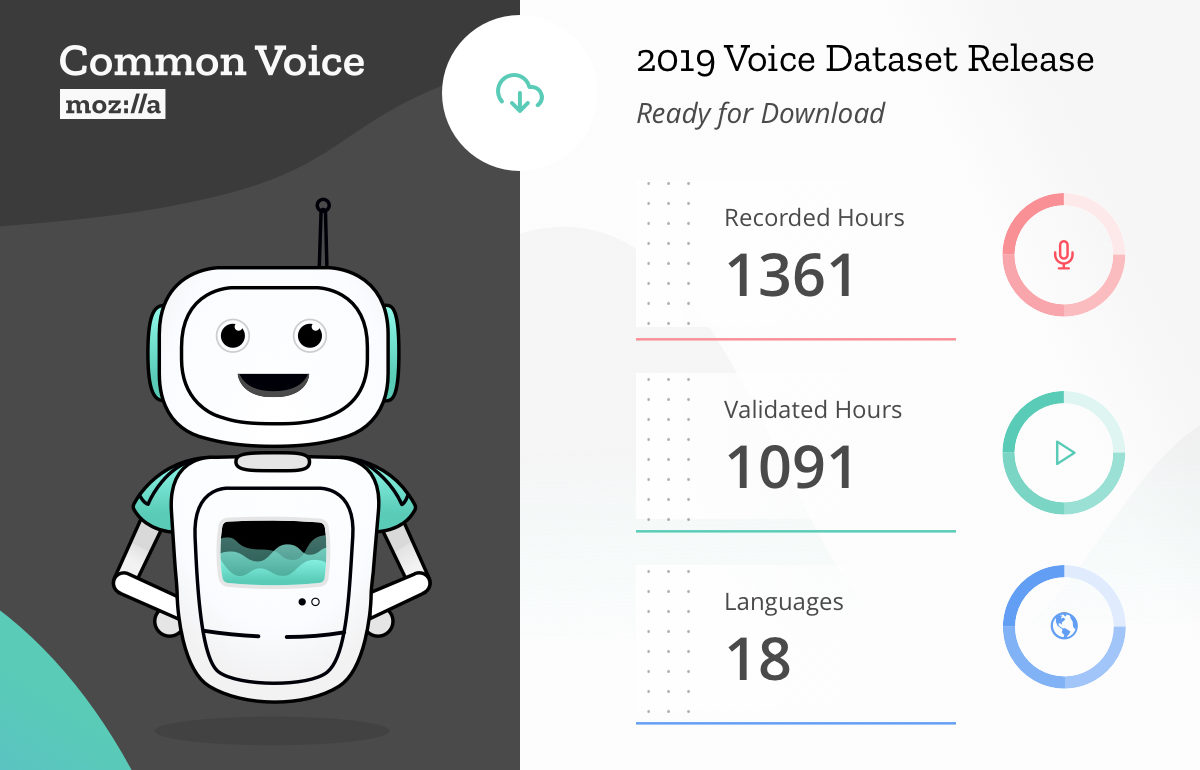
Mozilla Common Voice releases the largest to-date public domain voice dataset, including 18 languages, almost 1,400 hours of data from 42,000 contributors.
CourseChunks
updated 4 days ago
Comments
Related Chunks
Related chunks with this resource
Data Sets - How to find good Data Sets for AI training and Data Science
AI and speech recognition software - tools, resources - OpenAI, and more
RELATED RESOURCES
with chunks in common


2018
PredictHQ exits stealth with $10 million to help Uber and others forecast demand surges | VentureBeat
Saved by: CourseChunks
3 chunks
2019
Nvidia AI turns sketches into photorealistic landscapes in seconds – TechCrunch
Saved by: CourseChunks
5 chunks
2019
Google releases AI training data set with 5 million images and 200,000 landmarks | VentureBeat
Saved by: CourseChunks
3 chunks

2017
a16z Podcast: The Product Edge in Machine Learning Startups – 2017 - Andreessen Horowitz
Saved by: CourseChunks
3 chunks
No comments yet. Be the first to comment!